For whom?
One old good friend of mine, whom I respect a lot and who is a very good C++ programmer, recently asked me to give him an example of how it's possible make new language features in Lisp. He's aware of Lisp's ability to invent new syntax, and he's also excited about C++11. So he wonders how is that possible to introduce new syntax into your language all by yourself, without having to wait for the committee to adopt the new feature.
I decided to write this article for C++ programmers, explaining core Lisp ideas. It's a suicide; I'm sure as heck that I'll fail. Great number of excellent publications on Lisp for beginners exist, and still there are people who cannot grasp what's so special about it.
Nevertheless, I decided to try. Yet another article with introduction to Lisp won't harm anybody, nor will it make Lisp even less popular. Let's be honest: nobody reads this blog, anyway. :)
Why Lisp matters?
Lisp matters because that's a language which gives a programmer the
possibility to extend its own syntax. That's as if you could invent
new keywords in C++, for example, or special syntax for std::map
literals:
std::map<std::string, int> m1 = {
map:
("one", 1), ("two", 2), ("three", 3)
};
std::map<std::string, int> m2;
m2["one"] = 1;
m2["two"] = 2;
m2["three"] = 3;
typedef std::map<std::string, int>::value_type vtype;
vtype things[] = [vtype("one", 1),
vtype("two", 2),
vtype("three", 3)];
std::map<std::string, int> m3(
&things[0],
things + sizeof(things)/sizeof(things[0]));
All the m1, m2 and m3 are equal. The first example features a new syntax for giving std::map literals; I made it up, it doesn't really exist. Just imagine that we could invent it ourselves.
Why Lisp matters for C++ programmers?
Any sufficiently complicated C or Fortran program contains an ad hoc, informally-specified, bug-ridden, slow implementation of half of Common Lisp. |
|
| Greenspun's tenth rule | |
And you're right: we were not out to win over the Lisp programmers; we were after the C++ programmers. We managed to drag a lot of them about halfway to Lisp. Aren't you happy? |
|
| Guy Steele (on Java) |
Lisp has something that C++ has always wanted to have. Lisp is (to some extent) something that C++ has always striving to become. Lisp contains some forgotten ideas which were popular in early days of computing and went into oblivion as programming became more popular. Lisp will give you some useful insights that you won't find anywhere else.
Is Lisp a silver bullet then?
Certainly not. If it were, no new programming languages would have been appearing after 1962.
I won't go into details about deficiencies of Lisp. That's another problem to be discussed; an extremely painful problem, in fact. Just keep in mind that I'm not claiming C++ is shit and Lisp is a rose.
What are fundamental difficulties with understanding Lisp?
If you're a C++ programmer wanting to understand how a language can be so flexible that it enables to introduce new syntax, there are some fundamental difficulties for you to understand Lisp as an instance of such language. That's because Lisp is not "C++ + the ability to define new syntax". Lisp is much different from C++ in ways that have nothing to do with syntactic extensions. I mean, dynamic typing, functions as first-class values, no OOP in the first place, no templates, etc.
When a C++ programmer starts to delve into some Lisp introduction, he usually advances up to the point where Lisp looks completely alien and impractical, and then he's not able to move any forward. Syntactic extensions, as you guess, lie long after the point where the C++ programmer stops.
So, what makes Lisp look alien and impractical to our C++ programmer?
-
Dynamic typing. The dilemma of static/dynamic typing is one of those half-philosophy-half-programming questions that are not going to be resolved in favor of either side any time soon.
I believe that Lisp core ideas are incompatible with the idea of static typechecking, at least with mandatory typechecking. I cannot explain why, without explaining those core ideas themselves. Instead, let's try to look at static type systems in the following light.
A static type system is something non-primary to programming, something additional, ancillary. Imagine an interpreter for a simple toy language: you give the interpreter a piece of code and it just executes (evaluates) the code. Static typing means that before running or compiling, there must be an additional phase of processing – type checking. That's why static typing is not necessary; there are dynamic languages without it, such as Python or JavaScript. As a downside of it, these languages have to perform type checks at runtime. For example, in Python you just write:
def process(a, b): return a + b + 20without anywhere mentioning types of a and b. But when "+" gets executed in the course of your program run, it has to make sure a and b are actually numbers.Yeah, I know, you're saying that's bad. Having to check types dynamically over and over again instead of just checking them once is bad. I agree to some extent. But I want you to pick up 1 thing: static typing is not something vital to programming. It's not vital in the business of making computer do what you want. Static types are useful and arguably superior to dynamic types, but they are not necessary. It's an additional feature which is good and fine but not necessary.
Lots Of Idiotic Silly Parentheses.
Lisp has all the visual appeal of oatmeal with fingernail clippings mixed in.
Larry Wall Which is more readable:
a[x] += b[x-1] + 3 * b[x+1];
or:
(aset a x (+ (aref a x) (aref b (- x 1)) (* 3 (aref b (+ x 1)))))Those parentheses seem to be obfuscating everything. Yes, I agree that Lisp is superficially less readable than most traditional languages. "Superficially" means that Lisp looks worse for uninitiated, unprepared and inexperienced people; once you get some experience with it, you learn to see past paretheses.
But generally, that's true that Lisp looks ugly, especially Common Lisp. Although there are some nicer dialects, like Scheme or Clojure.
Why does Lisp look ugly to normal people? Ironically enough, this ugliness is the price we pay for being able to introduce new syntax. Lisp cannot have special syntax as C++ does, because in a language where anyone can create new features and DSLs, no syntax is special. In fact, many people claim that Lisp "has no syntax". This really means that Lisp has uniform syntax: every piece of code is just a list delimited with parentheses.
To know what the list really is and what it means, one must look at its head element:
- if the head is the name of a function, the list is just a function call form, and remaining elements are arguments to the function;
- if the head is the name of a special (core) operator, then this list is a special form with special meaning. There's a fixed number of special operators (26 in Common Lisp, 5 in Scheme, about 27 in Emacs Lisp). Special operators roughly correspond to keywords in C++. They are generally these: assignment, looping constructs (like while/until/for), introduction of local variables, lambda, throw/catch. Note that primitive operators like +, -, / and * are ordinary functions in Lisp and are not special in any way;
- if the head is the name of a macro, the list is a special syntax construct which is to be translated into a special operator form or a function call form (one of the above 2). How this is done is the point of this article and is described below.
Now I hope you see at least some justification why Lisp is ugly.
Only lists.
Some folks after initial acquaintance with Lisp make erroneous conclusion that list is the only composite data structure available in the language. Indeed, Lisp stands for "LISt Processing", so it's all about lists.
No! Lisp programs manipulate all kinds and diversities of data structures; this depends on concrete Lisp dialect you're using. Common Lisp has C-style structures, vectors and growable vectors, multidimensional arrays, strings, complex numbers and even objects and classes.
So, why are lists special then?
Lists are special only because code is represented with lists. That's all about them. You can have lists of numbers, of strings, of anything you want (lists are heterogeneous because of dynamic typing). And a piece of code is also a list! That's why lists are special. Code can be manipulated as data – that's the cornerstone of Lisp, its heart.
When you regard a list as code, you typically call it "a form". So "form" means "list which is treated as code".
It is not compiled
Some C++ programmers (I believe not very many of them, by now) can hardly imagine how it's possible not to have a phase of compilation. If you're one of those, I'm trying now to convince you: compilation is not necessary, much in the same way as static typing is not necessary.
What is compilation? It is translation into low-level code. There are 2 ways to run a program: either run it directly with a special runner, or have it translated into machine-level language and run it directly by the hardware. The first way is interpretation, and the "runner" is conventionally called "an interpreter"; the second way is compilation, and the program which performs translation is compiler.
The distinction between interpretation and compilation is not strict. Consider byte-codes. Your program can be compiled into byte-code, and the byte-code is interpreted by a special byte-code interpreter. Moreover, there's also JIT which means that compilation can take place on-the-fly and is optional.
C++ is a performance-oriented language. It is unthinkable how it can be interpreted. Or is it not? Consider debuggers: they allow you to enter arbitrary C++ expressions into the Watches window. Each time the debugger stops, the value of expression is reevaluated and displayed into that window. How does the debugger do it? The debugger interprets the expression. Oh, excuse me: it can actually compile it, and then rerun the code each time it needs to. In this case, debugger is somehow able to compile C++ code on-the-fly, and run it.
I believe you're a little bit more convinced now that even in C++ compile/interpret distinction is not very firm.
Compilation is not necessary: it is a preparational step aiming to improve performance of your program by translating it into lower-level language. C++ is special because it targets machine language for performance reasons, so compilation in the case of C++ is necessary. But it's not necessary in the general case.
Lisp can be both compiled and interpreted (even simultaneously); this depends on the implementation of a concrete dialect. For the purpose of this article, I won't talk about compilation of Lisp code except places where I intend to touch it explicitly. You can assume from now on that Lisp is interpreted, because thinking so is easier to get the idea of how it works. I promise I'll give special attention to compilation later.
Heart of Lisp: code is data
Enough about difficulties with Lisp. Let's get to Lisp itself.
In C++, your code is completely gone once it's compiled. Code is just a piece of text which is consumed by the preprocessor and compiler and is transformed (translated) into some machine-dependent representation and then executed.
In Lisp, code is live. Code is represented with certain data structures that you can manipulate by means of other code. Code is not gone when you compile your program. This opens up the possibility to implement new language features and do metaprogramming. You can write code that writes code, because "writing code" in Lisp is no different than "creating lists", and "running code" is the same as "evaluating lists".
By the way, in Lisp terminology, "evaluating" code means just "running" or "interpreting" code. Evaluation is orthogonal to the compilation/interpretation dualism. Evaluation has to do with carrying out computations; the compilation vs. interpretation thing is about how to carry out computations: directly or via preliminary translation.
Lisp is thus self-hosting: your Lisp program can create new Lisp programs or modify itself. Lisp has no compile-time/run-time distinction, and that's what the power of Lisp is all about. Even if a Lisp implementation provides compiler, there's still no compile-time/run-time dualism: you can run arbitrary Lisp code during compilation, and you can call compiler during the run-time of your program. That means you can bake functions out at run-time and compile them (with all optimizations), and then call them.
Evaluation of function call forms
So, now that you're supposed to be intrigued, let's talk about how code is actually represented as data structures, and how to do metaprogramming. Be patient: the trick is extremely simple, but unfortunately it cannot be explained as simply.
We shall begin with the notion of evaluation. As you know, in Lisp code is data, and "to run code" means "to evaluate data". Any kind of datum can be evaluated. But lists, as you guess, are of special interest.
Consider this piece of code:
(+ 10 20)
That's a list consisting of three items. The first one is the symbol "+", the second is number 10, and the third is number 20. (You don't know yet what "symbol" means, I'll get to it later. For now, symbol is a data type by which variables and identifiers are represented in programs.)
Let's enter (+ 10 20) at the REPL (Read-Eval-Print Loop). I'll use Emacs
Lisp:
ELISP> (+ 10 20) 30
We see that (+ 10 20) has evaluated to 30. How was
that done? Look at the bulleted list above, where I showed possible
kinds of forms. We have a list; its head element – symbol "+" – is the
name of a (primitive) function that adds numbers. So this list is a
function call form. The other 2 items are arguments: they are passed
to the function, which adds them and returns 30. Pretty simple,
yes?
ELISP> (+ 3 (* 2 4)) 11
This is also a function call form. But the third item of the list is itself a list (a nested list). This means that it must be evaluated before passing to the "+" function. So, the evaluation is carried out this way:
(+ 3 (* 2 4)) → (+ 3 8) → 11
ELISP> (+ (- 2 3) (* 2 4)) 7
That was also quite intuitive:
(+ (- 2 3) (* 2 4)) → (+ -1 (* 2 4)) → (+ -1 8) → 7
ELISP> (concat "I love " "programming"
(concat " despite of " "my" " age"))
"I love programming despite of my age"
(concat "I love " "programming"
(concat " despite of " "my" " age")) →
(concat "I love " "programming" " despite of my age") →
"I love programming despite of my age"
This is how function call forms are evaluated in Lisp: first the arguments are evaluated, in first-to-last order, then the function call is made. Arguments can be arbitrary expressions.
ELISP> 20 20 ELISP> "Luck" "Luck"
Simple numbers and strings are evaluated to themselves. In other words, they are self-evaluating.
Data types
A Lisp system operates with objects (not in the C++ sense); any datum is an object. Object have types stuck to them at run time (duck typing). Main object types are these:
- a number (integer or floating-point, for instance)
- a string
- a cons cell (a pair)
- a symbol
As it was mentioned above, all Lisp dialects allow for much wider range of types. But these 4 are exceptional, because they're indispensable and a key to the idea of Lisp. That's why we focus on these 4.
Numbers and strings are ordinary types, just like numbers and strings in any programming language. Strings are generally mutable in Lisp, as in C++.
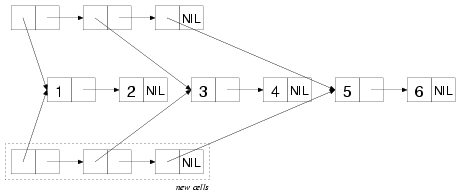
A cons cell (or a pair) is just an ordered pair of Lisp objects. First object and second object, which are historically called "CAR" and "CDR". Cells are implemented as a pair of pointers. Very simple: just 2 pointers.
Cons cells are important because that's what lists are made of. In Lisp, lists are singly-linked. A list is just a cons cell whose CAR contains a pointer to arbitrary Lisp object, and whose CDR contains either pointer to the next cons cell or NIL, which is a special thing (symbol) to denote empty lists:

Consider this:
struct cons_t {
int car;
cons_t *cdr;
};
Lisp cells are somewhat like above cons_t structure. But there's one important difference: this is just a convention that CDR was chosen to store a link. You should always keep in mind that CAR and CDR of a cons cell can contain anything.
Generally speaking, cons cells make arbitrary tree structures:

A symbol is a structure with 4 slots:
- name
- value
- function value
- property list
Slots can be accessed with certain functions that accept symbol as the sole argument. Name is an immutable slot and always contains a string which is the name of the symbol. All the other slots are mutable.
Symbols are important because they are what identifiers are represented with. When you implement new Lisp syntax, you're generating trees of cons cells which contain symbols, numbers and strings at some definite places.
(If you know some Ruby, then Lisp symbols are exactly the same thing as Ruby symbols.)
Reading
When you enter an expression at the REPL, the first thing which is done to it is reading. "Reading" means transforming a piece of text that you typed in into Lisp data.
When you enter a number or a string at the REPL, corresponding Lisp object is created and then evaluated:
234 reads as <Lisp number 234> "Luck" reads as <Lisp string Luck>
Reading of cons cells is a little bit more complicated:
(a . b) reads as:(a1 a2 a3 a4) reads as:
(a1 a2 a3 . a4) reads as:

That is, lists are read recursively. As soon as an open parenthesis is encountered, the reader makes a recursive call to itself to read the next object, whatever it is. The dot is used to delimit CAR and CDR in a cell.
A symbol is produced when the reader encounters something that doesn't look like a number and doesn't start with parenthesis.
number-of-times reads as <Symbol named "number-of-times"> name reads as <Symbol named "name"> your-age reads as <Symbol named "your-age">
Symbols are interned, in the same way as string literals can be interned by some C++ compilers. More exactly: there can be at most 1 symbol with a given name. Let S be a string; if a symbol with the name S does not exist yet, then it will be created by the reader when it tries to read S for the first time. After this moment, whenever the reader reads S again, it will produce the same symbol.
To illustrate the point of symbol interning, let's use the eq function; it tests any 2 Lisp objects for identity (and is typically implemented as just pointer comparison):
ELISP> (eq (read "your-age") (read "your-age")) t(Here, we did actually call the function read explicitly. This is the same function which is called implicitly by the REPL implementation when it reads our input. So there's nothing unusual here.)
You see that reading 2 equal strings produces the same Lisp object. "t" stands for "true", and "nil" is "false": these 2 are special symbols.
Symbols are different from cons cells and strings with respect to reading: when strings and cons cells (lists) are read, fresh objects are produced each time. See this:
ELISP> (eq (read "\"vasya\"" "\"vasya\"") nil ELISP> (eq (read "(10 20)") (read "(10 20)")) nil ELISP> (eq (read "(10 . 20)") (read "(10 . 20)")) nil ELISP> (eq (read "vasya") (read "vasya")) t
Symbols in Lisp correspond to identifiers in other languages, but because of Lisp's liberal reader syntax, symbols can contain all characters except for some special ones, like parentheses and quote ('):
ELISP> (read "1+1") 1+1 ELISP> (read "number->string") number->string ELISP> (read "class%") class%
Evaluation of symbols
Earlier I said that any Lisp datum can be evaluated. You've learned that strings and numbers are self-evaluating. Symbols are different: they evaluate to their value slot. That is, when Lisp evaluates a symbol, the result is whatever is stored in its value slot. For example:
ELISP> your-age *** Eval error *** Symbol's value as variable is void: your-age ELISP> (set 'your-age 12) 12 ELISP> your-age 12 ELISP> (set 'your-age '(10 20 30)) (10 20 30) ELISP> your-age (10 20 30)
The symbol "your-age" had an unbound value slot initially, that's why we got the error. Unbound symbols cause an error to be signaled when they're evaluated. Then we put the number 12 into the symbol's value slot, and evaluated the symbol. The function set accepts 2 arguments: a symbol and any other Lisp object. It stores the object into the symbol's value slot. You'll soon see better ways to give values to symbols.
Evaluation of quote
If you've been attentive enough all that long, you should remember that we've considered evaluation of function call forms, and there are 2 other kinds of forms that we haven't touched yet: special forms and macro forms.
Special forms differ among Lisp dialects. The most important special operator, which is present in all of them, is quote:
ELISP> (quote 20) 20 ELISP> (quote (i still dont get lisp)) (i still dont get lisp) ELISP> (quote (20 + 30)) (20 + 30) ELISP> (quote (+ 30 20 (- 10))) (+ 30 20 (- 10))
So what is quote doing? Nothing! It's there to prevent evaluation. The syntax of quote is like this:
(quote SUBFORM)
When such a form is evaluated, the result is SUBFORM, without
evaluation. Compare these:
ELISP> (quote (+ 20 30)) (+ 20 30) ELISP> (+ 20 30) 50 ELISP> (quote (+ 1 2 3)) (+ 1 2 3) ELISP> (+ 1 2 3) 6 ELISP> (quote your-age) your-age ELISP> your-age (10 20 30)
So quote acts in a pretty straightforward way: it just returns the
second element of the list, whatever an object it is. Consequently,
for self-evaluating objects quote is not necessary:
ELISP> 20 20 ELISP> (quote 20) 20 ELISP> "love" "love" ELISP> (quote "love") "love"
Do you see how quote is different from an ordinary function call form? Evaluation semantics is different: for a function call form, first all the arguments are evaluated in order and then the function is called, wherever in the case of a special form, not all arguments are necessarily evaluated. Moreover, the arguments of a special form are typically given certain meaning and are sometimes required to be lists of certain shape. That's what's called syntax in Lisp parlance.
Remember our previous example with reading symbols and comparing their identity?
ELISP> (eq (read "love") (read "love")) t ELISP> (eq (quote love) (quote love)) t ELISP> (quote love) love ELISP> love *** Eval error *** Symbol's value as variable is void: love
When a variable (== a symbol) goes by itself, you get its value; when it is quoted, you get the variable itself. Kind of meta-something, isn't it? It really is. Keep reading.
quote is used quite often in Lisp programming, that's why there's
special reader syntax for it: a single quote ('):
ELISP> (eq 'love (quote love)) t ELISP> (quote (quote (1 2 3))) '(1 2 3) ELISP> (first '(1 2 3)) 1 ELISP> (first ''(1 2 3)) quote
'OBJECT is just an abbreviation for (quote
OBJECT). first is a function that returns the first element of
a list.
let, let*, progn, if and cond
Let's learn syntax and semantics of some other special operators.
let and let* are like this:
(let (BINDING ...) FORM-1 FORM-2 ... FORM-N)
where each BINDING is a 2-element list (VAR VAL). Each VAR must be
a symbol. let is evaluated like this: first all VALs are evaluated in
order, then all VARs get bound to their respective VALs (via storing
VALs in VARs' value slots), then all FORM-i are evaluated in order. Values of all FORMs except FORM-N are discarded, and the value of
FORM-N is returned as the value of the whole let form. After FORM-N is
evaluated, all the symbols VAR-n are restored to the values which they
had before evaluating let.
let* is like let, but bindings are established sequentially: first
VAL-1 is evaluated and stored into VAR-1,
then VAL-2 is evaluated and stored in VAR-2,
and so on.
(progn FORM-1 .. FORM-n) == (let () FORM-1 ... FORM-n)
progn is Lisp's analog for block statement in C-like languages
(curly braces). (progn) is evaluated to nil.
Now branching constructs.
(if TEST THEN ELSE-1 .. ELSE-n).
TEST form is evaluated: if it is nil, then (progn ELSE-1 ... ELSE-n) is evaluated; if not nil, THEN is evaluated. So, for the
purpose of testing, all Lisp objects except nil are considered
true.
(cond CLAUSE ...) CLAUSE ::= (TEST) | (TEST FORM-1 .. FORM-N)
cond is like a chain of nested ifs. First, TEST of the first
clause is evaluated. If it produces true (non-nil object), then all
FORM-1 ... FORM-n are evaluated as in progn. In case when TEST is the
sole element of its clause (so the clause is 1-element list), then the
value of TEST itself is returned. If TEST evaluates to nil, then the
next clause is considered, and so on. If no clause succeeds, the
cond's value is nil.
lambda and symbols as functions
lambda is not a special operator, it is anonymous function. More
precisely, lambda is just an ordinary list which starts with the
lambda symbol:
(lambda PARAM-LIST FORM-1 .. FORM-N)
Lists which start with the lambda symbol can be called as
functions. When a lambda function is called, all the parameter
symbols are bound to respective factual arguments, and FORMs are
evaluated as in progn. Then parameters are restored to
their previous values.
It is important to understand that lambdas cannot be evaluated (in classical Lisp that I'm talking about in this article). They can appear as head (first) elements of function call forms, just like symbols that designate functions:
ELISP> ((lambda (x) (+ x 10))
20)
30
We have already seen symbols used as function names in function call forms. This works because symbols can be treated as functions by referring to their function value slot. So, whenever a symbol appears as the head of a function call form, the Lisp system takes its function value slot and uses it as a function (i.e., calls it with the specified arguments).
In other words, symbols are not first-class functions, they're only
names of functions. First-class functions are lambdas and primitives.
Primitives (subroutines) are present in every Lisp implementation and
are typically written in C. Core functions
like cons, car, cdr, +, *, eq
are typically primitives.
We can examine the function value of a symbol (i.e., contents of
its function value slot) via the function symbol-function:
ELISP> (symbol-function '+) #<subr +> ELISP> (symbol-function 'eq) #<subr eq>
Here, #<subr ...> designates subroutine. Subroutines are
separate type of Lisp objects, one of those which don't matter for our
discussion (because they are implementation-specific).
lambda parameter list
Lambdas accept parameters of the following shape:
(m-1 m-2 .. m-n [&optional opt-1 .. opt-m] [&rest rest])
Details differ among Lisp dialects. In Emacs Lisp, which I'm focusing on, things work like this:
ELISP> ((lambda (m1 m2 &optional opt1 opt2 &rest rest)
(list m1 m2 opt1 opt2 rest))
10 20)
(10 20 nil nil nil)
ELISP> ((lambda (m1 m2 &optional opt1 opt2 &rest rest)
(list m1 m2 opt1 opt2 rest))
10 20 30)
(10 20 30 nil nil)
ELISP> ((lambda (m1 m2 &optional opt1 opt2 &rest rest)
(list m1 m2 opt1 opt2 rest))
10 20 30 40)
(10 20 30 40 nil)
ELISP> ((lambda (m1 m2 &optional opt1 opt2 &rest rest)
(list m1 m2 opt1 opt2 rest))
10 20 30 40 50)
(10 20 30 40 (50))
ELISP> ((lambda (m1 m2 &optional opt1 opt2 &rest rest)
(list m1 m2 opt1 opt2 rest))
10 20 30 40 50 60 70 80 90)
(10 20 30 40 (50 60 70 80 90))
ELISP> ((lambda (m1 m2 &optional opt1 opt2 &rest rest)
(list m1 m2 opt1 opt2 rest))
10)
*** Eval error *** Wrong number of arguments: (lambda (m1 m2 &optional
opt1 opt2 &rest rest) (list m1 m2 opt1 opt2 rest)), 1
I hope you get the idea: there are mandatory and optional parameters, and also a special &rest-argument, which is assumed to be the tail of the list which remains after all mandatory and optional arguments have been consumed by their respective formal parameters.
Lisp is Lisp-2
This kind of Lisp is sometimes called Lisp-2, because there are 2 namespaces: for values and for functions, which means that any symbol can be simultaneously a function name and have a value which has nothing to do with its use as a function:
ELISP> (let ((+ 10)
(- 20))
(+ + -))
30
As you know, a symbol which is at the head of a form, is taken its
function value, whereas if a symbol appears at any other place, it is
evaluated by taking its usual value (the value slot). In the example
above, when (+ + -) is evaluated, the
first + acts as a usual summation operator, but the other
2 symbols – + and - – are regarded as
values. Those values are 10 and 20.
By now, we've seen only how it is possible to call functions which are situated at the head position of a form; the function itself could be either a symbol or a lambda. But what if we want to call a function as a value? For example, we want to make a function which applies some other function to the first two elements of a list:
ELISP> (defun app (f list)
(funcall f (first list) (second list)))
app
ELISP> (app '+ '(10 20 30 40))
30
ELISP> (app '+ '(10 20 30 . 40))
30
funcall is a special function which calls its first argument (which
must be a function) giving it all the other arguments. Being an
ordinary function, funcall receives its first argument evaluated. In
such a way we can use values as functions.
In the example above, (funcall f (first list) (second list)) is not
the same as (f (first list) (second list)): in the first case, we
evaluate symbol f in the normal way (by taking its value slot), and
then call whatever we got as a function. In the second case, we call
the function designated by the symbol f, and this has nothing to do
with the argument f that we received.
Manipulation with lists
If you're not asleep and still alive, I've got a good news for you: we have almost come to the point where you're supposed to see how to implement new language features.
But implementing new language features is done via manipulations with lists, so we must first learn some functions that manipulate lists.
Three basic functions to work with lists are cons, car and cdr.
consmakes a new cons cell whose CAR and CDR parts refer to the first and second arguments, respectively:ELISP> (cons 10 20) (10 . 20) ELISP> (cons 30 nil) (30) ELISP> (cons 30 '()) (30) ELISP> (cons 'a 'b) (a . b)
carandcdrreturn CAR and CDR parts of a cons cell:ELISP> (car '(10 . 20)) 10 ELISP> (cdr '(a . b)) b
There are also a plenty of other functions. Here are some:
listreturns a list of its arguments:ELISP> (list 10 20 30) (10 20 30) ELISP> (list) nil
appendconcatenates all the lists given to it, and returns a single great list:ELISP> (append '(10 20) '() '(30 40)) (10 20 30 40) ELISP> (append '() '() '(30 40)) (30 40) ELISP> (append '(10 20) '(a) '()) (10 20 a)
Evaluation of macro forms
Finally we got to macros. A macro form is a form (a list) whose CAR is a symbol designating a macro. We don't know yet what macros are, so let's talk a little bit about them.
A macro is not a first-class object in Lisp, which is surprising enough. A macro is a syntactic transformer which is created like this:
(defmacro NAME PARAM-LIST FORM-1 .. FORM-n)
Technically speaking, after evaluation of defmacro, NAME's function
value slot is assigned a cons cell (MACRO . transformer) – that is, a
cons cell whose CAR is the symbol macro (literally), and CDR is a
function which is actual syntactic transformer.
When (NAME arg-1 .. arg-n) is evaluated, the Lisp system sees that
NAME's function slot contains this kind of cons cell, and knows that
NAME is really a macro name, so the whole form is a macro form. What
happens now is this:
- arg-1, .., arg-n are passed unevaluated to the macro transformer
- whatever the macro transformer returns is assumed to be the new form to be evaluated (including a new macro form, of this macro or another, which is to undergo the same process recursively until something other than a macro form is returned).
So macros are different from functions in 2 crucial ways:
- they receive their arguments unevaluated. This means that what they get as arguments are actual pieces of code rather than whatever this code has been evaluated to
- they return not a final value but a piece of code which is to be evaluated in place of the original macro form.
Examples of macros
Let's see some (very simple) examples of macros:
ELISP> (let ((a 10))
(when (> 12 10)
(set 'a (* a 10))
a))
100
When is like this: (when TEST a-1 .. a-n). If TEST passes, all a-1, ... a-n are evaluated as in progn. If TEST is nil, then the whole when form returns nil.
When's counterpart is unless, which works the other way around with
respect to TEST:
ELISP> (let ((a 10))
(unless (> 12 10)
(set 'a (* a 10))
a))
nil
ELISP> (let ((a 10))
(unless (< 12 10)
(set 'a (* a 10))
a))
100
So, how would you implement when and unless? That's simple:
(defmacro when (test &rest forms) (list 'if test (cons 'progn forms))) (defmacro unless (test &rest forms) (cons 'if (cons test (cons 'nil forms))))
See what when and unless are doing? They're making lists out of
cons cells. Lists of certain structure. We can see what when and
unless are expanded to:
ELISP> (macroexpand-1
'(unless (< 12 10)
(set 'a (* a 10))
a))
(if (< 12 10)
nil
(set 'a (* a 10))
a)
ELISP> (macroexpand-1
'(when (< 12 10)
(set 'a (* a 10))
a))
(if (< 12 10)
(progn
(set 'a (* a 10))
a))
In this case, they got expanded into an if special form. So when
and unless are expressed in terms of if.
More advanced macro: stopwatch
Stopwatch is a special syntax for measuring how long a piece of code takes to execute:
(stopwatch ... SOME CODE ... ... AND CODE ... ... AND MORE CODE ...)
This returns how much time was spent executing this piece of code
(which is evaluated like progn):
ELISP> (stopwatch (list 1 2 3)) 2.1457672119140625e-06
Stopwatch is implemented this way:
(defmacro stopwatch (&rest forms)
`(let* ((start (float-time)))
(progn . ,forms)
(- (float-time) start)))
You see some new reader syntax here: it's called quasi-quoting. Instead of a usual single quote, there's a backquote which is placed in front of a list structure. It functions in exactly the same way as a single quote does, but additionally it's possible to mark some parts of code (at arbitrary depth in the tree) to be evaluated. This is done with comma and is called unquoting:
ELISP> `(1 2 3 4) (1 2 3 4) ELISP> `(1 2 (+ 3 4) 5) (1 2 (+ 3 4) 5) ELISP> `(1 2 ,(+ 3 4) 5) (1 2 7 5) ELISP> `(1 2 (+ ,(* 3 3) 4) 5) (1 2 (+ 9 4) 5)
More exactly, a "`" (backquote) quotes a form, except for nested subforms marked with "," (comma) which are evaluated.
The reader transforms backquote into some system-defined macro, and this macro, when expanded, analyzes the cons tree looking for nested commas. According to where commas are placed, the code is transformed to use some well-defined functions on lists, like append, list and cons above, and of course ordinary quoting (with single quotes). The resulting code, when evaluated, produces the specified list structure; forms marked with commas are evaluated:
ELISP> (macroexpand-all '(defmacro stopwatch (&rest forms)
`(let* ((start (float-time)))
(progn . ,forms)
(- (float-time) start))))
(defmacro stopwatch (&rest forms)
(cons 'let*
(cons
'((start
(float-time)))
(cons
(cons 'progn forms)
'((-
(float-time)
start))))))
macroexpand-all is a function that expands all the macros in a cons tree (working recursively to the full depth of it).
In this example, forms was unquoted and that's why you see forms
being evaluated above. All the other parts of the tree are quoted with
usual quotes.
In other words, backquote and unquote are Lisp's template system.
Unfortunately, I cannot give more examples of what can be done with Lisp macros, because this article got very large and there are lots of much better sources where you can get this information. The list of recommended reading is at the bottom of the article.
As a summary, I'm going to say that implementing new syntax in classical Lisp is not very easy. It's all about manipulating cons cells, and much of this work is done via quasiquoting which we have just used. There is some (great!) further work in this direction, such as Scheme programming language, which is arguably a next-generation Lisp. But for the purpose of this article, you can consider yourself enlightened if you understood how this is at all possible to write code that writes code.
Lisp is not ultimately unique in its class. Things that are naturally connected with Lisp include:
- XSLT which is XML which processes other XML
- JavaScript Function constructor, which accepts function body as a string and compiles it into a Function object
- any scripting language supporting eval
- the Tcl programming language.
Macros and compilation
Macros have special feature that has to do with compilation: when Lisp code is compiled, macros are expanded (as if with macroexpand-all). I mean, they're expanded at compile time. And you know that macroexpansion is operation that can run arbitrary Lisp code for the sake of producing expansion. So macroexpanders are pieces of code which run during compile time.
As I promised, a couple of words about Lisp compilation. Lisp can be compiled, and Common Lisp, Scheme, Clojure and all the other mature Lisps actually are. Common Lisp even allows optional type declarations which are used by the compiler to produce more effecient code. I believe JIT compilation is a very important technique for improving performance of any dynamic language, and this technique has not yet been explored sufficiently well. JavaScript seems to be the first dynamic language which was considerably sped up by employing clever JIT compiler optimizations.
Modern Lisps
What was described in this article is a kind of classical Lisp of 1962. I used Emacs in examples, but I didn't use any Emacs-specific features. This flavor of Lisp is primitive and lame, the barebone Lisp. For example, there are no native support for closures in such a language. Closures and lexical scoping first appeared in Scheme among Lisp dialects.
Since 1962, the whole family of different Lisps have been created. They all share the same trait: representing code as data and ability to manipulate this data. But there are very many points in which they differ. That's because the word Lisp doesn't mean something fixed, rigidly defined. The word really stands for a single idea, and there exist many ideas other than this which can be implemented in a single language. Many of those are mutually exclusive, like dynamic vs lexical scoping, and there are Lisp dialects based upon dynamic scoping and lexical scoping.
Conclusion
As I mentioned earlier, I don't expect this article to convince more than probably 2% of C++ programmers who are going to read it. That's not because C++ programmers are stupid, certainly. Rather because it is hard to explain things that people are unlikely to have come across anywhere else before.
Thanks for reading.